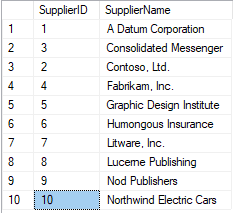
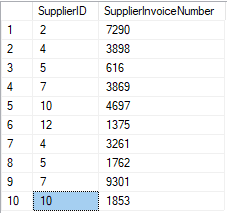
For this development, you are going to create a scenario, similar to a
school, with several tables, but without linking to each other.
You will need to have MySQL and MySQL WorkBench.
Use the following codes:
CREATE SCHEMA `dbo` ;
Then you can create the respective tables:
CREATE TABLE `classroom` (
`idClassroom` int(11) DEFAULT NULL,
`idCollege` int(11) DEFAULT NULL,
`description` varchar(50) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
CREATE TABLE `college` (
`idCollege` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
CREATE TABLE `professcls` (
`id` int(11) DEFAULT NULL,
`idClassroom` int(11) DEFAULT NULL,
`idProfessor` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
CREATE TABLE `professor` (
`idProfessor` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
CREATE TABLE `student` (
`idStudent` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
CREATE TABLE `studentcls` (
`id` int(11) NOT NULL,
`idClassroom` int(11) DEFAULT NULL,
`idProfessor` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3
Then, fill in the data:
Insert into dbo.student
(idstudent, name)
values
(1,’ANN’),
(2,’GEORGE’),
(3,’BEA’),
(4,’CRISTOPHER’);
Insert into dbo.Professor
(idProfessor, name)
values
(1,’Donald’),
(2,’Mary’),
(3,’Silvia’);
Insert into dbo.Classroom
(idClassroom, idCollege, description)
values
(1,1,’First’),
(2,1,’Second’);
Insert into dbo.College
(idCollege, name)
Values
(1,’King James’);
Insert into dbo.studentcls
(idStudent, idClassroom)
values
(1,1),
(2.1),
(3.2),
(4.2);
Insert into dbo.Professcls
(idProfessor, idclassroom)
values
(1,1),
(2.2);
The first thing to consider is that a database is proposed precisely to
avoid repeating data.
An Excel sheet could well be used and it would be much more functional
and faster than the development itself in a Database Management System,
however, this is not efficient, since the literals First, Second, King
James, Charles , Mary, Ann, George, Bea, and Cristopher, can be repeated
countless times.
And, precisely, one of the functions of a database is not to repeat
values, and to be able to gain efficiency.
JOIN two tables
Now you must assemble the SELECT query, first without caring about the
name of the columns or the constraints, just paying attention to the
relationships.
SELECT * FROM dbo.student INNER JOIN studentcls ON
student.idstudent = studentcls.idstudent;
And the following result is obtained:

Join three tables
Now you must add the following table, which cannot be other than the
Classroom.
You define their relationship by the columns indicated above.
SELECT name, idcollege, description FROM dbo.student
INNER JOIN studentcls ON student.idstudent = studentcls.idstudent
INNER JOIN classroom ON studentcls.idclassroom =
classroom.idclassroom;
Obtaining the following result:

And the result is that you have the same as in a Spreadsheet, but without
repeating data.
When a few thousand rows, it may not be very important, but with 20
million, the spreadsheet is no longer effective, and a database, with that
number of rows, begins to take center stage.






 You can write a query like this:
You can write a query like this: